Crawlkit
CrawlKit transforms the web into structured data with a single API call, empowering developers to extract and monitor.

About Crawlkit
CrawlKit is a revolutionary web data extraction platform designed specifically for developers and data teams seeking efficient and scalable access to web data. In an era where data-driven decisions are paramount, CrawlKit simplifies the complexities of web scraping, enabling users to collect data effortlessly without the need for intricate scraping infrastructures. It addresses common challenges such as rotating proxies, headless browsers, anti-bot measures, and rate limits, which often hamper data extraction efforts. With a single API call, users can extract a variety of data types—from raw page content to structured information from social platforms like LinkedIn and Instagram. By managing all the technical intricacies, CrawlKit allows you to focus on analyzing and utilizing the data effectively, unlocking the web's full potential for your projects and insights. Transform your data extraction process with CrawlKit, where simplicity meets functionality.
Features
Seamless API Integration
CrawlKit offers a simple HTTP API that integrates effortlessly with any programming language or platform. This flexibility means you can utilize the tool from your preferred environment without worrying about lock-in or compatibility issues.
Comprehensive Data Sources
With CrawlKit, you can extract structured data from a wide array of sources, including LinkedIn, Instagram, app stores, and more. A single API call enables you to retrieve detailed information across diverse websites and platforms, streamlining your data collection process.
Automatic Handling of Challenges
CrawlKit effectively manages complex scraping challenges such as proxy rotation, browser rendering, and rate limits. This automation allows you to focus solely on utilizing your data rather than dealing with the typical hurdles of web scraping.
Transparent and Flexible Pricing
CrawlKit offers a credit-based pricing model that ensures you know exactly what you pay for. With no hidden fees and credits that never expire, you can scale your data extraction needs without financial surprises, making it easy to manage your budget.
Use Cases
CRM Enrichment
Enhance your customer relationship management (CRM) system by automatically enriching it with data from LinkedIn profiles. CrawlKit can pull job titles, company information, and contact details, ensuring your leads are always up-to-date and relevant.
Competitive Analysis
Utilize CrawlKit to conduct thorough competitive intelligence by extracting data from competitors’ websites and social media profiles. You can monitor their strategies, follower counts, and engagement metrics, allowing you to make informed business decisions.
Market Research
Gather valuable insights for market research by easily extracting product reviews and ratings from app stores. CrawlKit allows you to analyze consumer opinions and trends, giving you a competitive edge in understanding the market landscape.
Social Media Growth Tracking
Track and analyze the growth of social media accounts with CrawlKit. By extracting follower counts, engagement data, and post performance from platforms like Instagram, you can gain insights into audience behavior and trends over time.
Frequently Asked Questions
What types of data can I extract using Crawlkit?
CrawlKit allows you to extract a variety of data types, including raw page content, structured data from social media platforms like LinkedIn and Instagram, and app store reviews. This versatility makes it suitable for numerous applications across different industries.
How does Crawlkit handle anti-bot measures?
CrawlKit is designed to navigate and bypass common anti-bot measures automatically. By managing proxy rotation and browser rendering, it ensures that your requests reach the target sites without being blocked, enabling seamless data extraction.
Is there a free trial available?
Yes, CrawlKit offers a free trial with 100 credits, allowing you to test the platform and its capabilities without any commitment. This trial is a perfect opportunity to explore how CrawlKit can meet your data extraction needs before making a financial commitment.
What if I need to extract data from a site not currently supported?
CrawlKit is committed to meeting user needs. If you require an API for a specific site that is not currently available, you can reach out to their support team, and they will work on building it for you, ensuring you have access to the data you need.
Similar to Crawlkit
Social Fetch API
Influencer API: scrape TikTok, Instagram, and YouTube profiles, posts, followers, and engagement. One social media scraper API, one JSON schema.
EnsembleData
Unlock real-time social media data at scale with EnsembleData's powerful, developer-friendly APIs.
Subiq
Subiq transforms chaotic SaaS spending into a single, clear dashboard so small teams can stop wasting money on forgotten tools and renewals.

Toon Tone
Toon Tone is a free daily memory game where you guess cartoon character colors using HSB sliders, enhancing your color perception skills.
FX Radar
FX Radar delivers real-time forex and financial news in seconds, empowering traders with powerful tools to analyze and optimize their performance.
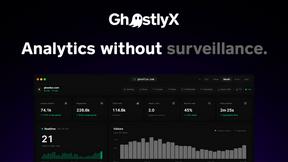
GhostlyX Privacy-First Web Analytics
GhostlyX unlocks transformative web analytics that deliver powerful, actionable insights while respecting every visitor's privacy without cookies.
Microplastic Intake App
Unlock your potential to transform health by tracking and minimizing microplastic intake with research-backed, data-driven precision.