Agenta vs OpenMark AI
Side-by-side comparison to help you choose the right AI tool.
Agenta transforms LLM development by centralizing workflows for collaboration, evaluation, and reliable AI app creation.
Last updated: March 1, 2026
OpenMark AI instantly benchmarks over 100 AI models on your exact task to find the best one for cost, speed, and quality.
Last updated: March 26, 2026
Visual Comparison
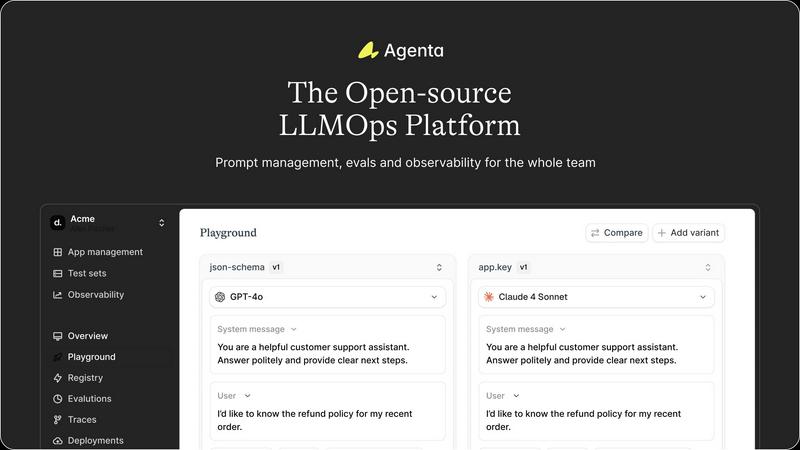
Agenta
OpenMark AI

Feature Comparison
Agenta
Centralized Workflow Management
Agenta centralizes all aspects of LLM development, including prompts, evaluations, and traces, into a single platform. This unification eliminates scattered workflows and provides a comprehensive overview of the project, enhancing collaboration among team members.
Unified Playground for Experimentation
The platform features a unified playground that allows teams to compare prompts and models side-by-side. This capability enables quick iterations and informed decision-making, as developers can visualize the performance of different models and make data-driven adjustments.
Automated Evaluation Processes
Agenta replaces guesswork with systematic, automated evaluation processes. Teams can create experiments, track results, and validate changes seamlessly, integrating multiple evaluators, including LLM-as-a-judge and custom evaluators, to ensure accuracy and reliability.
Real-Time Observability and Debugging
With Agenta, AI teams can trace every request and identify failure points in real-time. The platform facilitates the annotation of traces for collaborative debugging, turning any trace into a test with a single click, thus enabling teams to monitor performance and detect regressions efficiently.
OpenMark AI
Plain Language Task Description
Transform your workflow requirements into actionable benchmarks without writing a single line of code. Simply describe the task you want to test—from creative writing and translation to complex data extraction—in natural language. The platform's intuitive editor guides you in defining the task, enabling you to validate and run benchmarks in minutes, making advanced testing accessible to everyone on your team.
Multi-Model Benchmarking in One Session
Unlock unprecedented efficiency by testing the same prompt against a vast selection of 100+ leading LLMs simultaneously. This side-by-side comparison happens in a single, cohesive session, eliminating the need to manually switch between different provider dashboards and APIs. You get a unified view of performance, allowing for direct and immediate model-to-model analysis on your specific task.
Real Cost, Latency & Stability Metrics
Move beyond theoretical datasheets. OpenMark AI executes real API calls to each model, providing tangible metrics on actual cost per request and true latency. Its game-changing differentiator is measuring stability across repeat runs, showing you the variance in outputs. This reveals which models are consistently reliable versus those that just got lucky once, a critical factor for production applications.
Hosted Platform with Credit System
Accelerate your benchmarking journey by bypassing complex API key management. The platform operates on a simple credit system, so you don't need to configure or fund separate accounts with OpenAI, Anthropic, Google, or other providers. This hosted approach means you can start comparing models instantly, with all billing and infrastructure handled seamlessly through OpenMark AI.
Use Cases
Agenta
Rapid Prototyping of LLM Applications
Agenta enables AI teams to rapidly prototype LLM applications by providing a structured environment where they can experiment with prompts and models. This accelerates the development process and allows for quicker iterations based on real-time feedback.
Enhanced Collaboration Across Teams
By fostering collaboration among product managers, developers, and domain experts, Agenta ensures that all stakeholders are aligned in their objectives. This collaborative approach enhances the quality of AI products by integrating diverse insights and expertise throughout the development lifecycle.
Systematic Validation of AI Models
Agenta's automated evaluation features allow teams to systematically validate their AI models at each stage of development. This ensures that every change is backed by evidence and reduces the risk of deploying unreliable models into production.
Efficient Debugging and Issue Resolution
The observability tools provided by Agenta enable teams to debug their AI systems effectively. By tracing requests and annotating failures, teams can quickly identify and resolve issues, ensuring that their applications perform optimally in production environments.
OpenMark AI
Pre-Deployment Model Selection
Before integrating an AI feature into your product, definitively determine which model delivers the optimal balance of quality, cost, and speed for your specific use case. Test candidate models on your actual task prompts to see which one "actually gets it right," ensuring you ship with the most effective and efficient AI engine from day one.
Cost Efficiency Optimization for Scaling
When scaling an AI-powered feature, understanding the true cost dynamics is transformative. Benchmark models to analyze the trade-off between output quality and the actual price per API call. This allows teams to optimize for cost efficiency, potentially saving thousands by selecting a model that delivers nearly identical quality at a significantly lower operational expense.
Validating Output Consistency & Reliability
For applications where consistent, reliable outputs are non-negotiable—such as automated data entry, customer support responses, or content moderation—test model stability. OpenMark AI's repeat-run analysis shows variance, helping you identify and avoid models with high volatility, ensuring your users receive dependable and predictable performance every time.
Prototyping & Research for New AI Workflows
Rapidly prototype new AI capabilities by testing a wide range of models on novel tasks like complex agent routing, specialized research Q&A, or image analysis prompts. This exploratory benchmarking provides immediate, empirical data on what is possible, accelerating the research phase and informing architectural decisions without upfront API commitments.
Overview
About Agenta
Agenta is a groundbreaking, open-source LLMOps platform designed to revolutionize the way AI teams develop, manage, and deploy large language model (LLM) applications. In an era where unpredictable model behavior often leads to chaos, Agenta provides a robust solution by centralizing the entire LLM development lifecycle. This platform is tailored for developers, product managers, and domain experts who seek to collaborate effectively while navigating the complexities of LLMs. By offering integrated tools for prompt management, evaluation, and observability, Agenta empowers teams to experiment with confidence. Its unified environment eliminates silos, enabling systematic iteration and validation of each change, thus transforming the delivery of reliable AI products. With Agenta, teams can replace guesswork with data-driven insights and ensure swift resolution of issues, ultimately fostering innovation and productivity in AI development.
About OpenMark AI
Stop gambling on AI model selection. OpenMark AI is the definitive, game-changing platform for task-level LLM benchmarking, designed to eliminate guesswork before you ship. This transformative web application empowers developers and product teams to make data-driven decisions by testing AI models against their exact, real-world tasks. Simply describe what you need in plain language—be it classification, data extraction, RAG, or agent routing—and run comprehensive benchmarks across a vast catalog of 100+ models in a single, unified session. The platform delivers side-by-side comparisons of critical metrics like real API cost per request, latency, scored output quality, and, uniquely, stability across repeat runs. This reveals performance variance, ensuring you see consistent reliability, not a single lucky output. By using a hosted credit system, OpenMark AI removes the immense friction of configuring separate API keys for OpenAI, Anthropic, Google, and others, delivering genuine, uncached results from real API calls. It's built for those who prioritize cost efficiency (maximizing quality for your budget) over just the cheapest token price on a datasheet, fundamentally unlocking smarter, more confident pre-deployment AI decisions.
Frequently Asked Questions
Agenta FAQ
What types of teams can benefit from Agenta?
Agenta is designed for AI development teams, including developers, product managers, and domain experts. Its collaborative features make it suitable for any organization looking to streamline their LLM development process.
How does Agenta improve the LLM development lifecycle?
Agenta centralizes various aspects of LLM development, such as prompt management, evaluation, and observability. This integration helps teams move away from scattered workflows to a structured process, enhancing collaboration and efficiency.
Can Agenta integrate with existing tools and frameworks?
Yes, Agenta seamlessly integrates with popular frameworks and models, such as LangChain and OpenAI. This flexibility allows teams to continue using their preferred tools while benefiting from Agenta's powerful features.
Is Agenta suitable for both small and large teams?
Absolutely. Agenta is designed to cater to teams of all sizes, providing the necessary tools and infrastructure to support both small startups and large enterprises in their LLM development efforts.
OpenMark AI FAQ
How does OpenMark AI calculate costs?
OpenMark AI calculates costs by making real API calls to the model providers during your benchmark. It tracks the exact token usage (input and output) for each model on your specific task and applies the provider's latest public pricing. This gives you the actual, real-world cost per request, not an estimate or marketing number, for accurate financial planning.
What does "stability" or "variance" testing mean?
Stability testing refers to running the same task multiple times (in repeat runs) with the same model and prompt. OpenMark AI measures how much the outputs vary across these runs. Low variance indicates a stable, predictable model, while high variance suggests unreliable or "flaky" performance. This metric is crucial for production applications where consistency is key.
Do I need my own API keys to use OpenMark AI?
No, you do not need to configure or manage any external API keys. OpenMark AI operates on a hosted credit system. You purchase credits through the platform, and it handles all the API calls to providers like OpenAI, Anthropic, and Google on your behalf. This removes setup friction and allows for seamless, multi-provider benchmarking in one place.
What kind of tasks can I benchmark?
You can benchmark virtually any task that can be described in language. Common use cases include text classification, summarization, translation, data extraction from documents, question answering for RAG systems, agentic workflow routing, creative writing, code generation, and image analysis (for vision-capable models). The platform is designed to adapt to your unique requirements.
Alternatives
Agenta Alternatives
Agenta is an innovative open-source LLMOps platform designed to empower AI teams in creating reliable and production-grade LLM applications swiftly and confidently. It addresses the chaos often found in modern LLM development by providing a unified environment that promotes collaboration among developers, product managers, and domain experts. Users often seek alternatives to Agenta for various reasons, including pricing concerns, specific feature requirements, or the need for a platform that better aligns with their unique workflows. When considering an alternative, it is essential to evaluate factors such as ease of use, integration capabilities, scalability, and the overall support offered by the platform to ensure it meets your team's specific needs.
OpenMark AI Alternatives
OpenMark AI is a transformative developer tool for task-level LLM benchmarking. It empowers teams to make data-driven decisions by running real prompts against a vast catalog of models, comparing critical metrics like cost, latency, quality, and output stability in a single, unified session. Users often explore alternatives for various reasons, such as budget constraints, the need for different feature sets like on-premise deployment, or a preference for integrating benchmarking directly into their existing development workflow. The landscape of AI evaluation tools is rapidly evolving, offering different approaches to a common challenge. When evaluating alternatives, focus on what truly matters for your project. Key considerations include whether the tool provides real, non-cached API results, the breadth and depth of the model catalog, the granularity of performance and stability metrics, and how the platform aligns with your team's workflow and security requirements.