Agenta
Agenta transforms LLM development by centralizing workflows for collaboration, evaluation, and reliable AI app creation.
AI tool Details
Explore More
Alternatives
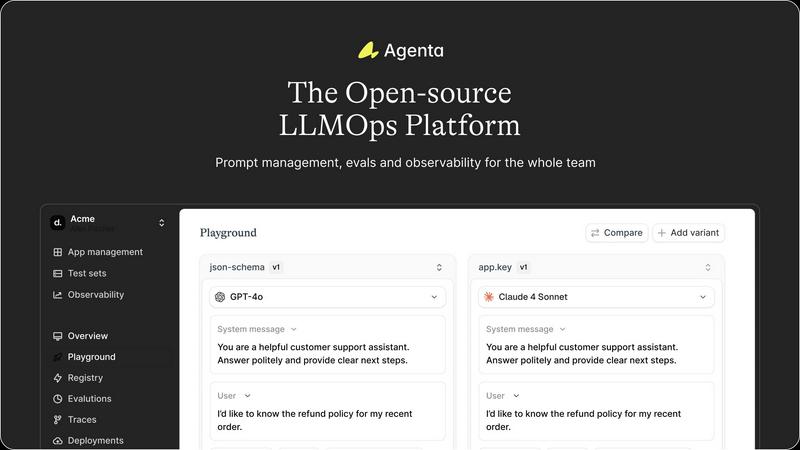
About Agenta
Agenta is a groundbreaking, open-source LLMOps platform designed to revolutionize the way AI teams develop, manage, and deploy large language model (LLM) applications. In an era where unpredictable model behavior often leads to chaos, Agenta provides a robust solution by centralizing the entire LLM development lifecycle. This platform is tailored for developers, product managers, and domain experts who seek to collaborate effectively while navigating the complexities of LLMs. By offering integrated tools for prompt management, evaluation, and observability, Agenta empowers teams to experiment with confidence. Its unified environment eliminates silos, enabling systematic iteration and validation of each change, thus transforming the delivery of reliable AI products. With Agenta, teams can replace guesswork with data-driven insights and ensure swift resolution of issues, ultimately fostering innovation and productivity in AI development.
Features
Centralized Workflow Management
Agenta centralizes all aspects of LLM development, including prompts, evaluations, and traces, into a single platform. This unification eliminates scattered workflows and provides a comprehensive overview of the project, enhancing collaboration among team members.
Unified Playground for Experimentation
The platform features a unified playground that allows teams to compare prompts and models side-by-side. This capability enables quick iterations and informed decision-making, as developers can visualize the performance of different models and make data-driven adjustments.
Automated Evaluation Processes
Agenta replaces guesswork with systematic, automated evaluation processes. Teams can create experiments, track results, and validate changes seamlessly, integrating multiple evaluators, including LLM-as-a-judge and custom evaluators, to ensure accuracy and reliability.
Real-Time Observability and Debugging
With Agenta, AI teams can trace every request and identify failure points in real-time. The platform facilitates the annotation of traces for collaborative debugging, turning any trace into a test with a single click, thus enabling teams to monitor performance and detect regressions efficiently.
Use Cases
Rapid Prototyping of LLM Applications
Agenta enables AI teams to rapidly prototype LLM applications by providing a structured environment where they can experiment with prompts and models. This accelerates the development process and allows for quicker iterations based on real-time feedback.
Enhanced Collaboration Across Teams
By fostering collaboration among product managers, developers, and domain experts, Agenta ensures that all stakeholders are aligned in their objectives. This collaborative approach enhances the quality of AI products by integrating diverse insights and expertise throughout the development lifecycle.
Systematic Validation of AI Models
Agenta's automated evaluation features allow teams to systematically validate their AI models at each stage of development. This ensures that every change is backed by evidence and reduces the risk of deploying unreliable models into production.
Efficient Debugging and Issue Resolution
The observability tools provided by Agenta enable teams to debug their AI systems effectively. By tracing requests and annotating failures, teams can quickly identify and resolve issues, ensuring that their applications perform optimally in production environments.
Frequently Asked Questions
What types of teams can benefit from Agenta?
Agenta is designed for AI development teams, including developers, product managers, and domain experts. Its collaborative features make it suitable for any organization looking to streamline their LLM development process.
How does Agenta improve the LLM development lifecycle?
Agenta centralizes various aspects of LLM development, such as prompt management, evaluation, and observability. This integration helps teams move away from scattered workflows to a structured process, enhancing collaboration and efficiency.
Can Agenta integrate with existing tools and frameworks?
Yes, Agenta seamlessly integrates with popular frameworks and models, such as LangChain and OpenAI. This flexibility allows teams to continue using their preferred tools while benefiting from Agenta's powerful features.
Is Agenta suitable for both small and large teams?
Absolutely. Agenta is designed to cater to teams of all sizes, providing the necessary tools and infrastructure to support both small startups and large enterprises in their LLM development efforts.
Similar to Agenta
JavaScript Tools
JSTools.Space is a free collection of privacy-first developer utilities for formatting code, inspecting JSON and tokens, generating secure values, enc
Headless Domains
Headless Domains empowers AI agents with secure, verifiable identities to foster trust across applications and marketplaces.
LoadTester
LoadTester unlocks your team's potential by transforming HTTP and API load testing into a game-changing, zero-infrastructure experience.
ProcessSpy
ProcessSpy unlocks advanced macOS process monitoring with powerful filtering, real-time insights, and native performance.
Claw Messenger
Claw Messenger empowers your AI agent with its own iMessage number for seamless, instant communication across any platform.